Check top / htop for Load and CPU Steal
If you’re experiencing high load, top and htop will both make identifying the primary sites pretty easy – you’ll see your site’s system user in the user column.
These two programs will give you a live overview of exactly what’s going on on your server. You’ll see individual PHP processes and MySQL CPU usage, and this can be a good indicator of whether you’re experiencing high load or not, and whether it’s mostly your database or PHP.
Using top you can also check for CPU steal (and iowait):
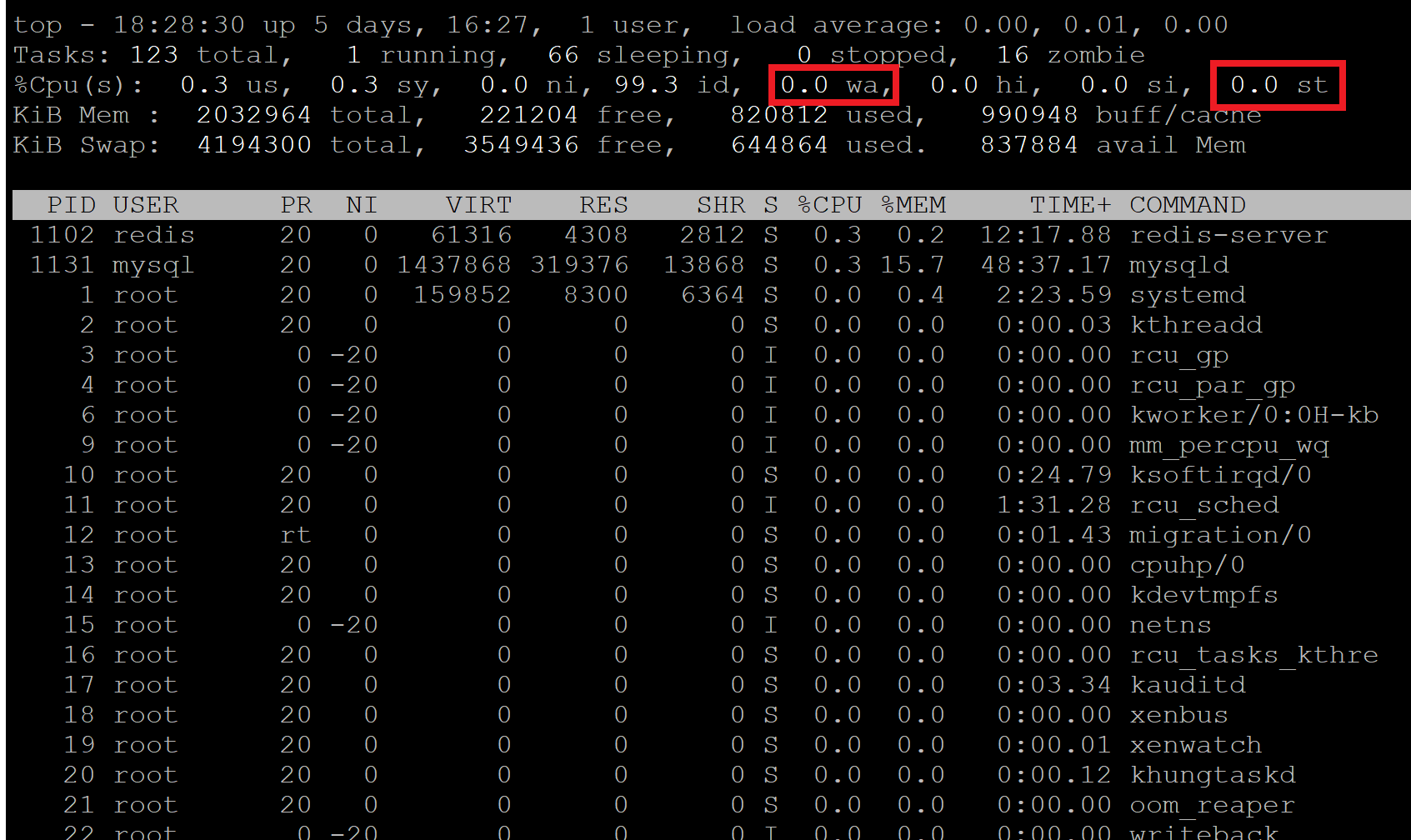
If either of these are high, then you’ll suffer performance issues. Steal (st) means that another VPS on your server is using more than it’s allocated CPU usage and it’s infringing on your own resources (contact your server provider and let them know you’re suffering steal).
I/O Wait means some processes are running via disk instead of RAM, and if this is high then the CPU is waiting on the IO/drives, which is highly inefficient. Your server needs more RAM to cope with the workload.
To dig deeper into top and htop, you can check out the following article:
Freeing Up Disk Space
Letting your disk space fill up can have serious consequences. At best, MySQL will go down, and all your sites will go down with it. At worst, you’ll suffer irreversible MySQL damage. The latter scenario you’ll need to fall back to your server provider snapshot.
Disk Space Checks
First, you need to identify what’s taking up so much disk space. You’ll want to check: –
- Your backups
- Your websites /wp-content directory
- Your database sizes
- Server logs
- Site logs
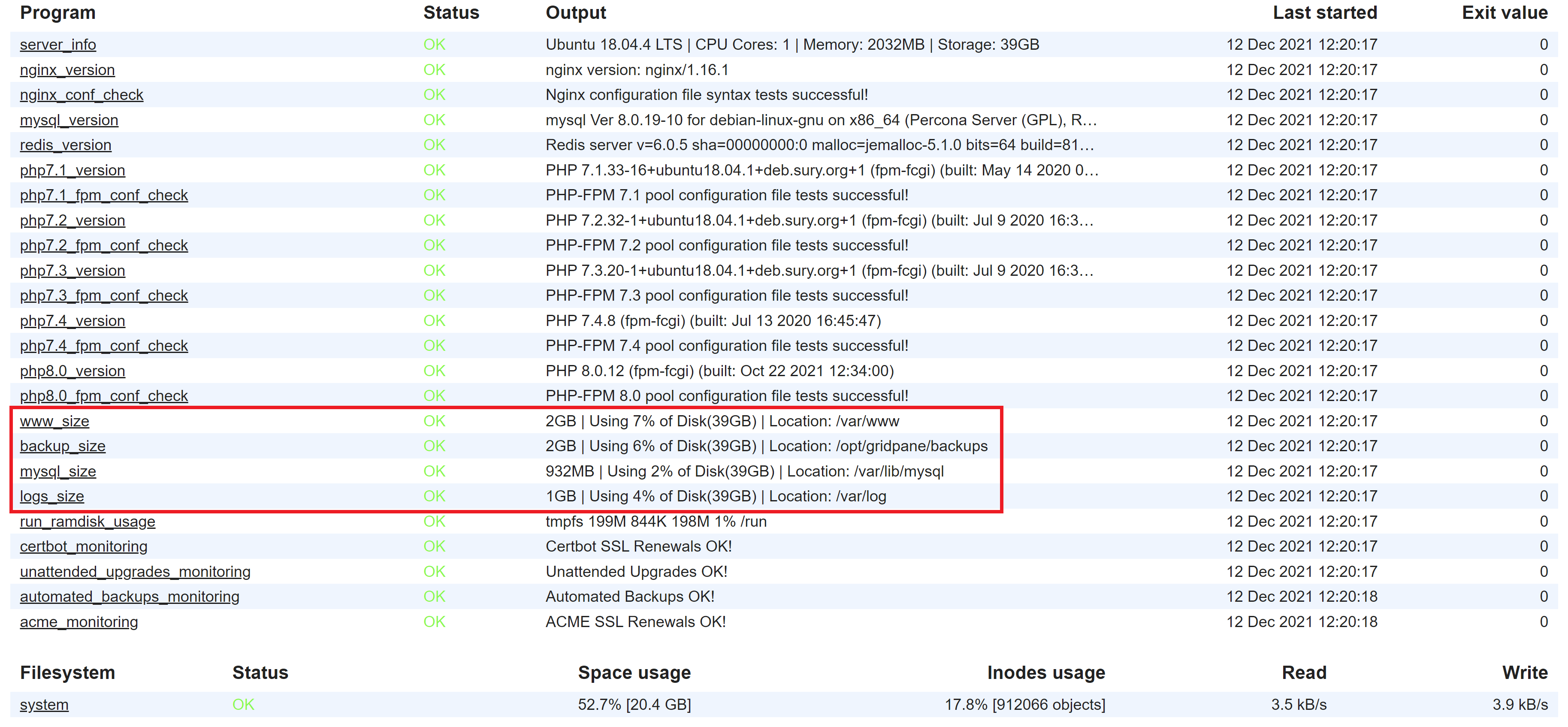
Monit will provide a quick overview of where you should start:
Check Your Website Directories
You can check which websites are the largest on your server by running:
cd /var/www
And then:
du -h --max-depth=1 | sort -h
When you identify the largest site, navigate to its directory with (switch out site.url with your websites actual URL):
cd /var/www/site.url/
Logs may be the cause – remove them if that’s the case. Also, turn off wp-debug to remove its log if it’s been active for some time.
You’ll like next navigate to /htdocs directory and then /wp-content and from there, plugin backups (which may have their own directory) are a common cause. Some optimization plugins can also have large caches.
Check Your Database Sizes
Check your database sizes by first navigating to:
cd /var/lib/mysql
And then:
du -h --max-depth=1 | sort -h
Clean Up Backups
Once you’ve identified the largest sites you may be able to clean up some space quickly by pruning some of their backups.
Removing Files via SSH
Remove files with rm command. For example:
rm bigfile.zip
To remove files recursively (for example, if you need to delete an entire directory and its contents), use the -r flag like so:
rm -r backups-folder
You can learn more in this knowledge base article:
Troubleshooting High Disk Space Usage and Locating Large Files